Posts tagged ‘valued networks’
The added benefit of network data: Assessing impact of suppliers and buyers on CDS spreads
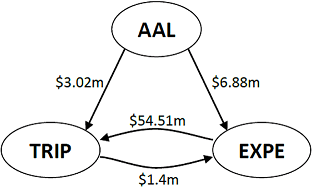 Networks has the potential to increase the explanatory power of models. The content of this post, and accompanying paper, quantifies the size of this effect for predicting the financial health of companies. It is my hope that it can help drive more research into networks and enable more organizations to develop better models and understand interdependencies to a greater extent.
Networks has the potential to increase the explanatory power of models. The content of this post, and accompanying paper, quantifies the size of this effect for predicting the financial health of companies. It is my hope that it can help drive more research into networks and enable more organizations to develop better models and understand interdependencies to a greater extent.
Companies do not operate in a vacuum. As companies move towards an increasingly specialized production function and their reach is becoming truly global, their aptitude in managing and shaping their inter-organizational network is a determining factor in measuring their health. Current models of company financial health often lack variables explaining the inter-organizational network, and as such, assume that (1) all networks are the same and (2) the performance of partners do not impact companies. This paper aims to be a first step in the direction of removing these assumptions. Specifically, the impact is illustrated by examining the effects of customer and supplier concentrations and partners’ credit risk on credit-default swap (CDS) spreads while controlling for credit risk and size. We rely upon supply-chain data from Bloomberg that provides insight into companies’ relationships. The empirical results show that a well diversified customer network lowers CDS spread, while having stable partners with low default probabilities increase spreads. The latter result suggests that successful companies do not focus on building a stable eco-system around themselves, but instead focus on their own profit maximization at the cost of the financial health of their suppliers’ and customers’. At a more general level, the results indicate the importance of considering the inter-organizational networks, and highlight the value of including network variables in credit risk models.
Continue Reading February 23, 2016 at 1:20 am Leave a comment
Article: Triadic closure in two-mode networks: Redefining the global and local clustering coefficients
 A paper called “Triadic closure in two-mode networks: Redefining the global and local clustering coefficients” that I have authored will be published in the special issue of Social Networks on two-mode networks (2012).
A paper called “Triadic closure in two-mode networks: Redefining the global and local clustering coefficients” that I have authored will be published in the special issue of Social Networks on two-mode networks (2012).
As the vast majority of network measures are defined for one-mode networks, two-mode networks often have to be projected onto one-mode networks to be analyzed. A number of issues arise in this transformation process, especially when analyzing ties among nodes’ contacts. For example, the values attained by the global and local clustering coefficients on projected random two-mode networks deviate from the expected values in corresponding classical one-mode networks. Moreover, both the local clustering coefficient and constraint (structural holes) are inversely associated to nodes’ two-mode degree. To overcome these issues, this paper proposes redefinitions of the clustering coefficients for two-mode networks.
Why Anchorage is not (that) important: Binary ties and Sample selection
 A surprising finding when analysing airport networks is the importance of Anchorage airport in Alaska. In fact, it is the most central airport in the network when applying betweenness! I do not believe this finding is completely accurate due to two reasons: (1) there is a potential for measurement error when not including tie weights (i.e., assigning the same importance to the connection between London Heathrow and New York’s JFK as to the connection between Pack Creek Airport and Sitka Harbor Sea Plane Base in Alaska), and (2) relying on US data only leads to sample selection as the airport network is a global system. This post highlights how to use a weighted betweenness measure as well as the extent of the sample selection issue.
A surprising finding when analysing airport networks is the importance of Anchorage airport in Alaska. In fact, it is the most central airport in the network when applying betweenness! I do not believe this finding is completely accurate due to two reasons: (1) there is a potential for measurement error when not including tie weights (i.e., assigning the same importance to the connection between London Heathrow and New York’s JFK as to the connection between Pack Creek Airport and Sitka Harbor Sea Plane Base in Alaska), and (2) relying on US data only leads to sample selection as the airport network is a global system. This post highlights how to use a weighted betweenness measure as well as the extent of the sample selection issue.
Degree Centrality and Variation in Tie Weights
 A central metric in network research is the number of ties each node has, degree. Degree has been generalised to weighted networks as the sum of tie weights (Barrat et al., 2004), and as a function of the number of ties and the sum of their weights (Opsahl et al., 2010). However, all these measures are insensitive to variation in the tie weights. As such, the two nodes in this diagram would always have the same degree score. This post showcases a new measure that uses a tuning parameter to control whether variation should be taken favourable or discount the degree centrality score of a focal node.
A central metric in network research is the number of ties each node has, degree. Degree has been generalised to weighted networks as the sum of tie weights (Barrat et al., 2004), and as a function of the number of ties and the sum of their weights (Opsahl et al., 2010). However, all these measures are insensitive to variation in the tie weights. As such, the two nodes in this diagram would always have the same degree score. This post showcases a new measure that uses a tuning parameter to control whether variation should be taken favourable or discount the degree centrality score of a focal node.
Article: Node centrality in weighted networks: Generalizing degree and shortest paths
 A paper called “Node centrality in weighted networks: Generalizing degree and shortest paths” that I have co-authored will be published in Social Networks. Ties often have a strength naturally associated with them that differentiate them from each other. Tie strength has been operationalized as weights. A few network measures have been proposed for weighted networks, including three common measures of node centrality: degree, closeness, and betweenness. However, these generalizations have solely focused on tie weights, and not on the number of ties, which was the central component of the original measures. This paper proposes generalizations that combine both these aspects. We illustrate the benefits of this approach by applying one of them to Freeman’s EIES dataset.
A paper called “Node centrality in weighted networks: Generalizing degree and shortest paths” that I have co-authored will be published in Social Networks. Ties often have a strength naturally associated with them that differentiate them from each other. Tie strength has been operationalized as weights. A few network measures have been proposed for weighted networks, including three common measures of node centrality: degree, closeness, and betweenness. However, these generalizations have solely focused on tie weights, and not on the number of ties, which was the central component of the original measures. This paper proposes generalizations that combine both these aspects. We illustrate the benefits of this approach by applying one of them to Freeman’s EIES dataset.
Closeness centrality in networks with disconnected components
 A key node centrality measure in networks is closeness centrality (Freeman, 1978; Wasserman and Faust, 1994). It is defined as the inverse of farness, which in turn, is the sum of distances to all other nodes. As the distance between nodes in disconnected components of a network is infinite, this measure cannot be applied to networks with disconnected components (Opsahl et al., 2010; Wasserman and Faust, 1994). This post highlights a possible work-around, which allows the measure to be applied to these networks and at the same time maintain the original idea behind the measure.
A key node centrality measure in networks is closeness centrality (Freeman, 1978; Wasserman and Faust, 1994). It is defined as the inverse of farness, which in turn, is the sum of distances to all other nodes. As the distance between nodes in disconnected components of a network is infinite, this measure cannot be applied to networks with disconnected components (Opsahl et al., 2010; Wasserman and Faust, 1994). This post highlights a possible work-around, which allows the measure to be applied to these networks and at the same time maintain the original idea behind the measure.
Local clustering coefficient for two-mode networks
 Similar to the motivation of the global clustering coefficient that I proposed in Clustering in two-mode networks, the local clustering coefficient is biased if applied to a projection of a two-mode network. It is biased in the sense that the randomly expected value is not obtained on the projection of a random two-mode network. To overcome this methodological bias, I redefine the local clustering coefficient for two-mode networks. The new coefficient is a mix between the global clustering coefficient for two-mode networks and Barrat’s (2004) local coefficient for a weighted one-mode network. The coefficient is tested on Davis’ (1940) Southern Women dataset.
Similar to the motivation of the global clustering coefficient that I proposed in Clustering in two-mode networks, the local clustering coefficient is biased if applied to a projection of a two-mode network. It is biased in the sense that the randomly expected value is not obtained on the projection of a random two-mode network. To overcome this methodological bias, I redefine the local clustering coefficient for two-mode networks. The new coefficient is a mix between the global clustering coefficient for two-mode networks and Barrat’s (2004) local coefficient for a weighted one-mode network. The coefficient is tested on Davis’ (1940) Southern Women dataset.
Online Social Network-dataset now available
 The Online Social Network-dataset used in my Ph.D. thesis is now available on the Dataset-page. This network has also been described in Patterns and Dynamics of Users’ Behaviour and Interaction: Network Analysis of an Online Community and used in Prominence and control: The weighted rich-club effect and Clustering in weighted networks. The network originate from an online social network among students at University of California, Irvine. The edgelist includes the users that sent or received at least one message during that period (1,899). A total number of 59,835 online messages were sent among these over 20,296 directed ties.
The Online Social Network-dataset used in my Ph.D. thesis is now available on the Dataset-page. This network has also been described in Patterns and Dynamics of Users’ Behaviour and Interaction: Network Analysis of an Online Community and used in Prominence and control: The weighted rich-club effect and Clustering in weighted networks. The network originate from an online social network among students at University of California, Irvine. The edgelist includes the users that sent or received at least one message during that period (1,899). A total number of 59,835 online messages were sent among these over 20,296 directed ties.
Similarity between node degree and node strength
 This post explores the relationship between node degree and node strength in an online social network. In the online social network, heterogeneity in nodes’ average tie weight across different levels of degree had been reported
This post explores the relationship between node degree and node strength in an online social network. In the online social network, heterogeneity in nodes’ average tie weight across different levels of degree had been reported . Although degree and average tie weight are significantly correlated, this post argues for the similarity of degree and node strength. In particular, high pair-wise correlation between degree and strength is found. In addition, power-law exponents of degree distributions and strength distribution are reported. The exponents are strikingly similar, in fact, they are almost identical.
. Although degree and average tie weight are significantly correlated, this post argues for the similarity of degree and node strength. In particular, high pair-wise correlation between degree and strength is found. In addition, power-law exponents of degree distributions and strength distribution are reported. The exponents are strikingly similar, in fact, they are almost identical.
Continue Reading October 16, 2009 at 12:57 pm Leave a comment
Clustering in two-mode networks
Many network dataset are by definition two-mode networks. Yet, few network measures can be directly applied to them. Therefore, two-mode networks are often projected onto one-mode networks by selecting a node set and linking two nodes if they were connected to common nodes in the two-mode network. This process has a major impact on the level of clustering in the network. If three or more nodes are connected to a common node in the two-mode network, the nodes form a fully-connected clique consisting of one or more triangles in the one-mode projection. Moreover, it produces a number of modeling issues. For example, even a one-mode projection of a random two-mode network with same number of nodes and ties will have a higher clustering coefficient than the randomly expected value. This post represents an attempt to overcome this issue by redefining the clustering coefficient so that it can be calculated directly on the two-mode structure. I illustrate the benefits of such an approach by applying it to two-mode networks from four different domains: event attendance, scientific collaboration, interlocking directorates, and online communication.
tnet: Software for Analysing Weighted Networks
 tnet is a package written in R that can calculate weighted social network measures. Almost all of the ideas posted on this blog are related to weighted networks as, I believe, taking into consideration tie weights enables us to uncover and study interesting network properties. Not only are few social network measures applicable to weighted networks, but there is also a lack of software programmes that can analyse this type of networks. In fact, there are no open-source programmes. This hinders the use and development of weighted measures. tnet represents a first step towards creating such a programme. Through this platform, weighted network measures can easily be applied, and new measures easily implemented and distributed.
tnet is a package written in R that can calculate weighted social network measures. Almost all of the ideas posted on this blog are related to weighted networks as, I believe, taking into consideration tie weights enables us to uncover and study interesting network properties. Not only are few social network measures applicable to weighted networks, but there is also a lack of software programmes that can analyse this type of networks. In fact, there are no open-source programmes. This hinders the use and development of weighted measures. tnet represents a first step towards creating such a programme. Through this platform, weighted network measures can easily be applied, and new measures easily implemented and distributed.
Weighted Rich-club Effect: A more appropriate null model for scientific collaboration networks
 In this post, I extend the Weighted Rich-club Effect by suggesting and testing a different null model for the scientific collaboration network (Newman, 2001). This network is a two-mode network, which becomes an undirected one-mode network when projected. In the paper, we compared the observed weighted rich-club coefficient with the one found on random networks. The random networks were constructed by a null model defined for directed networks when prominence was based on node strength. Therefore, we created a directed network from the undirected scientific collaboration network by linking connected nodes with two directed ties that had the same weight. The null model consisted in reshuffling the tie weights attached to out-going ties for each node. However, this local reshuffling broke the weight symmetry of the two directed ties between connected nodes. The null model proposed in this post is based on the randomisation of the two-mode network before projecting it onto a one-mode network. By randomising before projecting, we are able to randomise a network while keeping the symmetry of weights.
In this post, I extend the Weighted Rich-club Effect by suggesting and testing a different null model for the scientific collaboration network (Newman, 2001). This network is a two-mode network, which becomes an undirected one-mode network when projected. In the paper, we compared the observed weighted rich-club coefficient with the one found on random networks. The random networks were constructed by a null model defined for directed networks when prominence was based on node strength. Therefore, we created a directed network from the undirected scientific collaboration network by linking connected nodes with two directed ties that had the same weight. The null model consisted in reshuffling the tie weights attached to out-going ties for each node. However, this local reshuffling broke the weight symmetry of the two directed ties between connected nodes. The null model proposed in this post is based on the randomisation of the two-mode network before projecting it onto a one-mode network. By randomising before projecting, we are able to randomise a network while keeping the symmetry of weights.
Projecting two-mode networks onto weighted one-mode networks
 This post highlights a number of methods for projecting both binary and weighted two-mode networks (also known as affiliation or bipartite networks) onto weighted one-mode networks. Although I would prefer to analyse two-mode networks in their original form, few methods exist for that purpose. These networks can be transformed into one-mode networks by projecting them (i.e., selecting one set of nodes, and linking two nodes if they are connected to the same node of the other set). Traditionally, ties in the one-mode networks are without weights. By carefully considering multiple ways of projecting two-mode networks onto weighted one-mode networks, we can maintain some of the richness contained within the two-mode structure. This enables researchers to conduct a deeper analysis than if the two-mode structure was completely ignored.
This post highlights a number of methods for projecting both binary and weighted two-mode networks (also known as affiliation or bipartite networks) onto weighted one-mode networks. Although I would prefer to analyse two-mode networks in their original form, few methods exist for that purpose. These networks can be transformed into one-mode networks by projecting them (i.e., selecting one set of nodes, and linking two nodes if they are connected to the same node of the other set). Traditionally, ties in the one-mode networks are without weights. By carefully considering multiple ways of projecting two-mode networks onto weighted one-mode networks, we can maintain some of the richness contained within the two-mode structure. This enables researchers to conduct a deeper analysis than if the two-mode structure was completely ignored.
Are triangles made up by strong ties?
 A key assumption of Granovetter’s (1973) Strength of Weak Ties theory is that strong ties are embedded by being part of triangles, whereas weak ties are not embedded by being created towards disconnected nodes. This assumption have been tested by calculating the traditional clustering coefficient on binary networks created with increasing cut-off parameters (i.e., creating a series of binary networks from a weighted network where ties with a weight greater than a cut-off parameter is set to present and the rest removed). Contrarily to theories of strong ties and embeddedness, these methods generally showed that the clustering coefficient decreased as the cut-off parameter increased. However, the binary networks were not comparable with each other as they had a different number of ties. Another way of testing this assumption is to take the ratio between the weighted global clustering coefficient and the traditional coefficient measured on networks where all ties are considered present. Thus, the number of ties is maintained. This post highlights this feature and empirically tests it on a number of publically available weighted network datasets.
A key assumption of Granovetter’s (1973) Strength of Weak Ties theory is that strong ties are embedded by being part of triangles, whereas weak ties are not embedded by being created towards disconnected nodes. This assumption have been tested by calculating the traditional clustering coefficient on binary networks created with increasing cut-off parameters (i.e., creating a series of binary networks from a weighted network where ties with a weight greater than a cut-off parameter is set to present and the rest removed). Contrarily to theories of strong ties and embeddedness, these methods generally showed that the clustering coefficient decreased as the cut-off parameter increased. However, the binary networks were not comparable with each other as they had a different number of ties. Another way of testing this assumption is to take the ratio between the weighted global clustering coefficient and the traditional coefficient measured on networks where all ties are considered present. Thus, the number of ties is maintained. This post highlights this feature and empirically tests it on a number of publically available weighted network datasets.
Article: Clustering in Weighted Networks
 A paper called “Clustering in Weighted Networks” that I have co-authored will be published in Social Networks. Although many social network measures exist for binary networks and many theories differentiate between strong and weak ties, few measures have been generalised so that they can be applied to weighted networks and retain the information encoded in the weights of ties. One of these measures is the global clustering coefficient, which measures embeddedness or, more specifically, the likelihood of a triplet being closed by a tie so that it forms a triangle. This article proposes a generalisation of this key network measure to weighted networks.
A paper called “Clustering in Weighted Networks” that I have co-authored will be published in Social Networks. Although many social network measures exist for binary networks and many theories differentiate between strong and weak ties, few measures have been generalised so that they can be applied to weighted networks and retain the information encoded in the weights of ties. One of these measures is the global clustering coefficient, which measures embeddedness or, more specifically, the likelihood of a triplet being closed by a tie so that it forms a triangle. This article proposes a generalisation of this key network measure to weighted networks.
The importance of allowing ties to decay
 Recently, a number of network dataset have been constructed from archival data (e.g., email logs) with the aim to study human interaction. This has allowed researchers to study large-scale social networks. If the archival data does not included information about the severing or weakening of ties, non-relevant interaction among people, which occurred far in the past, might be deemed relevant. This post highlights this issue and suggests imposing a lifespan on interactions to record only relevant ties with the current strength.
Recently, a number of network dataset have been constructed from archival data (e.g., email logs) with the aim to study human interaction. This has allowed researchers to study large-scale social networks. If the archival data does not included information about the severing or weakening of ties, non-relevant interaction among people, which occurred far in the past, might be deemed relevant. This post highlights this issue and suggests imposing a lifespan on interactions to record only relevant ties with the current strength.
Article: Patterns and Dynamics of Users’ Behaviour and Interaction: Network Analysis of an Online Community
 A paper called “Patterns and Dynamics of Users’ Behaviour and Interaction: Network Analysis of an Online Community” that I have co-authored will be published in the Journal of the American Society for Information Science and Technology (JASIST). In this paper, we studied the evolution of a variety of properties in an online community, including how users create, reciprocate, and deepen relationships with one another, variations in users’ gregariousness and popularity, reachability and typical distances among users, and the degree of local redundancy in the community.
A paper called “Patterns and Dynamics of Users’ Behaviour and Interaction: Network Analysis of an Online Community” that I have co-authored will be published in the Journal of the American Society for Information Science and Technology (JASIST). In this paper, we studied the evolution of a variety of properties in an online community, including how users create, reciprocate, and deepen relationships with one another, variations in users’ gregariousness and popularity, reachability and typical distances among users, and the degree of local redundancy in the community.
Betweenness in weighted networks
 This post highlights a generalisation of Freeman’s (1978) betweenness measure to weighted networks implicitly introduced by Brandes (2001) when he developed an algorithm for calculating betweenness faster. Betweenness is a measure of the extent to which a node funnels transactions among all the other nodes in the network. By funnelling the transactions, a node can broker. This could be by taking a cut (e.g. Ukraine controls most gas pipelines from Russia to Europe) or distorting the information being transmitted to its advantage.
This post highlights a generalisation of Freeman’s (1978) betweenness measure to weighted networks implicitly introduced by Brandes (2001) when he developed an algorithm for calculating betweenness faster. Betweenness is a measure of the extent to which a node funnels transactions among all the other nodes in the network. By funnelling the transactions, a node can broker. This could be by taking a cut (e.g. Ukraine controls most gas pipelines from Russia to Europe) or distorting the information being transmitted to its advantage.
Operationalisation of tie strength in social networks
 The method used to operationalise ties’ strength into weights affects the outcomes of weighted networks measures. Simply assigning 1, 2, and 3 to three different levels of tie strength might not be appropriate as this scale might misrepresent the actually difference among the three levels (using an ordinal scale). In this post, I highlight issues with collecting weighted social network data from surveys.
The method used to operationalise ties’ strength into weights affects the outcomes of weighted networks measures. Simply assigning 1, 2, and 3 to three different levels of tie strength might not be appropriate as this scale might misrepresent the actually difference among the three levels (using an ordinal scale). In this post, I highlight issues with collecting weighted social network data from surveys.
Weighted local clustering coefficient
 The generalisation of the local clustering coefficient to weighted networks by Barrat et al. (2004) considers the value of a triplet to be the average of the weights attached to the two ties that make up the triplet. In this post, I suggest three additional methods for defining the triplet value.
The generalisation of the local clustering coefficient to weighted networks by Barrat et al. (2004) considers the value of a triplet to be the average of the weights attached to the two ties that make up the triplet. In this post, I suggest three additional methods for defining the triplet value.
Average shortest distance in weighted networks
 The average distance that separate nodes in a network became a famous measure following Milgram’s six-degrees of separation experiment in 1967 that found that people in the US were on average 6-steps from each other. This post proposes a generalisation of this measure to weighted networks by building on work by Dijkstra (1959) and Newman (2001).
The average distance that separate nodes in a network became a famous measure following Milgram’s six-degrees of separation experiment in 1967 that found that people in the US were on average 6-steps from each other. This post proposes a generalisation of this measure to weighted networks by building on work by Dijkstra (1959) and Newman (2001).
Local weighted rich-club measure
This post proposes a local (node-level) version of the Weighted Rich-club Effect (PRL 101, 168702). By incorporating this measure into a regression analysis, the impact of targeting efforts towards prominent nodes on performance can be studied.
Network? Weighted network?
Networks are the cornerstone of this blog, therefore I have decided to make the first post my definition of a network and a few basic network measures.
 RSS feed
RSS feed
