The added benefit of network data: Assessing impact of suppliers and buyers on CDS spreads
February 23, 2016 at 1:20 am Leave a comment
Networks has the potential to increase the explanatory power of models. The content of this post, and accompanying paper, quantifies the size of this effect for predicting the financial health of companies. It is my hope that it can help drive more research into networks and enable more organizations to develop better models and understand interdependencies to a greater extent.
Abstract
Companies do not operate in a vacuum. As companies move towards an increasingly specialized production function and their reach is becoming truly global, their aptitude in managing and shaping their inter-organizational network is a determining factor in measuring their health. Current models of company financial health often lack variables explaining the inter-organizational network, and as such, assume that (1) all networks are the same and (2) the performance of partners do not impact companies. This paper aims to be a first step in the direction of removing these assumptions. Specifically, the impact is illustrated by examining the effects of customer and supplier concentrations and partners’ credit risk on credit-default swap (CDS) spreads while controlling for credit risk and size. We rely upon supply-chain data from Bloomberg that provides insight into companies’ relationships. The empirical results show that a well diversified customer network lowers CDS spread, while having stable partners with low default probabilities increase spreads. The latter result suggests that successful companies do not focus on building a stable eco-system around themselves, but instead focus on their own profit maximization at the cost of the financial health of their suppliers’ and customers’. At a more general level, the results indicate the importance of considering the inter-organizational networks, and highlight the value of including network variables in credit risk models.
1. Introduction
The inter-organizational network surrounding companies provides opportunities and constrains behavior. By creating an extensive network of customers and suppliers (collectively called partners), a company is likely to increase shareholder value by specializing on core products and services. This feature can be traced all the way back, for workers instead of organizations, to Adam Smith and division of labor. At an organizational level, similar effects are likely to impact companies’ performance and financial health. For example, the assembly of electronic products is becoming an increasingly international process, where components and technology are sourced from specialist suppliers. This process enables companies to focus on core skills, where return on investment and shareholder value are likely to be optimized.
A host of academic papers have applied a network perspective to identify and quantify the impact of inter-organizational networks on various success factors (Cross et al., 2003). According to the network perspective, organizations are embedded within networks of interconnected relationships. Different positions in a network are associated with a range of outcomes, such as imitation, adaptation, innovation, firm survival, and performance (Brass et al., 2004). For example, companies in a position of brokering between others have relatively higher returns (Bae and Gargiulo, 2004).
Unlike traditional perspectives that treat organizations as independent observations and focus simply on their attributes, network science incorporates additional structural information. These two perspectives are not mutually exclusive and can be combined to conduct a superior analysis by including variables based on network characteristics alongside attribute-based ones.
1.1. Concentration
The first feature of the inter-organizational network that this article attempts to tackle is concentration. For a company, concentrations can exist both on the customer-side and the supplier-side. These two aspects represents two different types of underlying risks. First, customer-concentration is an immediate threat to the revenue stream as a single or a select few customers provide the majority of revenue received. For example, Table 1 highlights the top customers of TripAdvisor. As Expedia represents more than a quarter of TripAdvisor’s revenue, TripAdvisor is vulnerable to two scenarios: (1) Expedia is in a position to squeeze its profit margins and (2) a substantial chunk of revenue would potentially be affected were Expedia to default, downsize, or restructure.
| Customers | Value | % Revenue |
|---|---|---|
| Expedia Inc | 54.51M | 25.63% |
| Priceline Group Inc/The | 42.17M | 19.83% |
| Orbitz Worldwide Inc | 11.56M | 5.44% |
| CTRIP.COM International Ltd | 10.20M | 4.79% |
| Google Inc | 3.25M | 1.53% |
| American Airlines Group Inc | 3.02M | 1.42% |
Table 1: Customers with a quantified relationship representing more than 1% of TripAdvisor Inc’s annual revenue
Second, concentration might also occur among suppliers. In this case, a default event could threaten business continuity and pose as a source of operational risk, which ultimately could be detrimental to the financial health of a company. Conversely to customer concentration that might imply a squeeze on the focal company’s profit margins through revenue reduction, supplier concentration could lead to cost increases.
1.2. Influence: Partners’ default probability
A key feature of networks is the relatively high number of ties among similar nodes (McPherson et al., 2001). This feature is often referred to as homophily. Two causal mechanisms lead to homophily: selection and influence
(Aral et al., 2009). First, similar nodes tend to form ties together (i.e., selection). Second, dissimilar nodes tend to become more similar over time if they are tied (i.e., influence). The latter feature is of key interest when understanding the consequences of the network as opposed to the mechanisms underpinning the network. An understanding of influence forms the basis for assessing and quantifying contagion, diffusion, and cascades.
From an inter-organizational network perspective, the financial health of companies’ partners could provide additional insight into their own financial health. Specifically, influence can be thought of as directly improving or worsening a company’s health (e.g., investment grade companies are more stable and thereby bring about less volatility to their partners). The lowering in volatility is likely to bring about a smaller risk premium, and as such, enable a smoother operation of the overall system. Conversely, the system might not be driven by global optimization, but by local optimization instead. Companies are likely to prioritize their own profit maximization (i.e., local optimization) at the expense of ensuring a stable overall ecosystem (i.e., global optimization). Given the opposing theoretical aspects, it is an empirical question of whether, and the extent to which, interacting with stable partners is positively or negatively related to financial health of companies.
The remainder of this article is organized as follows. First the methodology, including data collection and metric construction, is presented. This is followed by results. Finally, a conclusion and discussion section ends the paper with notes on general applicability, limitations, and avenues of future work.
2. Methodology
To model the effect of customer and supplier concentrations and partners’ credit risk on the financial health of companies, we apply a regression framework with credit-default swap (CDS) spreads as the dependent variable while controlling for credit risk and market cap. Our observations are all companies with 5-year CDS spreads on Bloomberg on April 29, 2014. This includes 828 companies. We limit our observations by excluding banks as they “lack a hard asset/manufacturing-type of supply chain” (Advisory note on the Bloomberg SPLC-screen when analyzing financial institutions). This implies removing 152 financial companies from the sample. As such, the total number of observations is 676. Additionally, we weight the observations by the reciprocal of companies’ logged market cap in billions to account for the fact that larger companies are more likely to be included in the sample than smaller companies. This alleviates potential correlation between the dependent variable and inclusion probability (Fuller, 2009) and enables a better understanding of the financial health of all companies instead of simply the ones that are more likely to have an observable 5-year CDS spread.
The sub-sections below provide details on the data collection and metric operationalization for quantifying the impact of the inter-organizational networks on CDS spreads. Note that all variables tend to be skewed and, as shown below for the dependent variable, transforming the variables by the natural logarithm of them lessens the skewness. For count variables (e.g., number of suppliers) with a potential zero score, the log is taken of 1 plus the variable. More details and distribution plots for all variables are found in the Appendix of the accompanying paper.
2.1. Dependent variable: CDS spreads
Success or performance of a company can be quantified by a number of metrics. A traditional risk framework view focuses on the financial health of companies by predicting default probabilities. These probabilities are often arrived at by modeling historical default events in a logistic-regression framework or applications of Merton’s structural default model. However, few companies, and especially large public companies, default. As such, these frameworks are hard to calibrate and exposed to rare-event bias.
To overcome potential biases, we choose an outcome variable that is quantified for a large number of companies and also closely related to the financial health of a company (Longstaff, 2005): CDS spread. Specifically, we use 5-year market CDS spread (in basis points; bps) as listed on Bloomberg under the Default Risk Monitor (DRAM)-view.
The distribution of the 5-year market CDS spreads is highly right-skewed (Figure 1a), but conforms closer to a Gaussian shape after transforming it with the natural logarithm (Figure 1b). This transformation of the dependent variable enables an ordinary least square (OLS) regression framework to be applied, which lessens the complexity of the model. A well-tested simple model allows us to focus on incorporating novel metrics to assess the impact of the inter-organizational network on the financial health of companies.
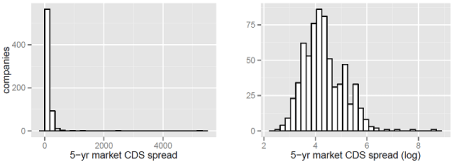
Figure 1: Distribution of 5-year market CDS spreads.
2.2 Inter-organizational network data
The interdependencies among companies are not straight-forward to measure, assess, and collect. In fact, maintaining the confidentiality of this information might be of strategic importance to the companies. For example, it could enable customers to circumvent the focal company by purchasing directly from its suppliers. Nevertheless, some companies publish their supply chain (e.g., Apple provides a list of their top 200 suppliers, see apple.com/supplierresponsibility/) and others’ become known through media coverage and quarterly reports.
One source that attempts to collect the interdependencies among companies is Bloomberg. The supply chain analysis (SPLC)-view gives an insight into the inter-organizational network in which a company operates by listing large suppliers, customers, and peers. The entities in the network are identified by combining Bloomberg analysts’ assessment, company reports, quarterly filings, company news releases, and media coverage. To gauge the coverage of this data, we performed an ad-hoc analysis of Apple’s top 200 suppliers-list. There are 695 suppliers listed in the Bloomberg data, and the intersection among these lists are 191 suppliers, which indicate a 95.5% coverage rate.
A number of identified relationships are quantified (e.g., Toyota Motors is 3M biggest customer responsible for 4.4% of their revenue). This information is, however, only populated for about 37% of the relationships identified. In total there are 100,030 relationships (63,001 supplier relationships and 37,029 customer relationships) for the included companies in this study. Out of these, 37,014 relationships are quantified (23,497 supplier relationships and 13,517 customer relationships). Moreover, the quality of these estimates is uncertain due to this information not being required in regulatory filings.
A key limitation of using this data for network analysis is the difficulty of extracting it for multiple companies. To overcome this limitation, we created a custom tools to aid this otherwise manual process.
2.3. Independent variables: Concentration
We consider three features when assessing concentration of customers and suppliers. First, the numbers of customers and suppliers are key to understand how concentrated an inter-organizational network is. This is akin to degree within the network science literature (Opsahl et al., 2010). An increase in these numbers is likely to suggest additional concentration as only large partners representing concentration are listed in Bloomberg.
Second, the distribution of relationship values tends to be skewed (e.g., see Table 1 for TripAdvisor Inc’s customers). Skewness brings about greater concentration that simply the number of partners.
Third, concentration can also arise through other companies. For example, both TripAdvisor and Expedia are suppliers to American Airlines, and since TripAdvisor and Expedia are mutually connected, American Airlines’ are further concentrated than what simply the number of suppliers and skewness would suggest.
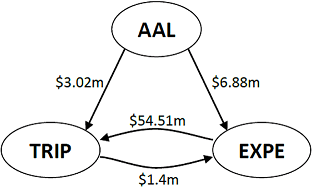
Figure 2: Triad among TripAdvisor Inc, Expedia Inc, and American Airlines Group Inc
To measure the concentrations of customers and suppliers, it is common to apply the Herfindahl index. For example, the SEC applies it to assess the competitiveness of sectors and creation of monopolies when considering whether or not to approve mergers. It is defined as the sum of squared proportions. The square ensures that a single large concentration weights more than many smaller ones. In our context, we use the percentage of revenue that a relationship represents for customer-concentration (percentage of total costs for supplier-concentration). In the example of customer-concentration for TripAdvisor (Table 1), the metric is the sum of 0.25632, 0.19832, 0.05442, 0.04792, 0.01532, 0.014222, and so on for all customers, which is about 11%. Formally, it is:
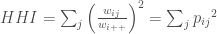
where $latexw_{ij}$ is the relationship value from company i to company j, 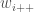
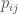
It is worth noting that the Herfindahl index does not consider the third feature listed above: indirect concentrations. To incorporate this feature, constraint, an advanced version of the Herfindahl index, is often used in network analysis (Burt, 1992). This metric comes from the structural holes literature and is formally defined as:
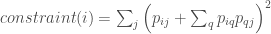
where q are companies indirectly connected to company i and company j. If there were no indirect connections, this metric would be equal to the Herfindahl index as the 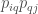
However, this metric requires a exponentially larger data collection effort as the network of all partner companies would need to be acquired. As such, we have computed five metrics for both customer and supplier lists:
- Number of companies
- Number of companies with a Bloomberg identifier, which are likely to be public companies
- Number of customers (suppliers) with percentage of revenue (cost) defined
- The sum of percentage of revenue (cost) that customers (suppliers) represent
- The Herfindahl Index
It is worth noting that the last two are only calculated on the subset of partners with a quantified relationship. As such, these metrics only consider about 37% of the relational data.
2.4. Independent variables: Influence
We consider the default probability of partners to test whether the financial health of partners impact the focal company. Specifically, we take the average of customers’ (suppliers’) Bloomberg-defined default probability derived from a structural Merton model. We chose this variable instead of CDS spreads as CDS spreads are only available for a limited sample of companies, and as such, would lead to sparse data issues and dropped observations. On the contrary, a default probability is available for the partners of 70% of relationships. Out of the total number of relationships, the partners of 69,637 relationships have a default probability (45,844 supplier relationships and 23,793 customer relationships).
For both suppliers and customers, we take a simple average and a weighted one. The weights are based on the percentage of revenue (costs) that the particular customer (supplier) represents. While the simple average is applied to about 70% of relationships, the weighted is only calculated on 21% (12%) of customer (supplier) relationships as the percentage of revenue (cost) is only available for 37% of relationships.
2.5. Control variables
To control for general financial information, we include the corporate default probability as derived by Bloomberg’s structural Merton model (Bloomberg, 2013). This variable is correlated with CDS spreads (pair-wise correlation of 0.40; R2 is 0.16 in a univariate model). In fact, it can be argued that these two variables are the same. However, the model-derived default probability only considers the independent variables used in the model, and the purpose of this paper is to highlight that inter-organizational network variables have the potential of increasing the explanatory power in a combined model.
Additionally, we include the market cap of companies as a proxy of size and the liquidity of the swaps. Larger companies are likely to provide more information to the market, be rated by a larger set of investors, and have more contracts with various maturity dates than smaller ones. As such, their CDS contracts are likely to be traded more frequently, which increases the liquidity.
We further control for the Global Industry Classification Standard (GICS) sector of the companies. This ensures that sectoral differences are parsed out.
Finally, indicator variables for the country of risk associated with the companies are included. This variable attempts to overcome spread differences due to countries. The country of risk is determined based on “four factors listed in order of importance: management location, country of primary listing, country of revenue and reporting currency of the issuer. Management location is defined by country of domicile unless location of such key players as Chief Executive Officer (CEO), Chief Financial Officer (CFO), Chief Operating Officer (COO), and/or General Counsel is proven to be otherwise”.
3. Results
The regression results from a select set of combination of variables are listed in Table 2. Model 1 is a baseline model without any inter-organizational variables. We find a strong link between default probability and CDS spreads. Together with country and sector indicator variables and market cap, this baseline or control model explains 68% of the variance in CDS spreads. In the Appendix, descriptive statistics and pair-wise correlation for the main variables are listed in Table 3 and results for the indicator variables are in Table 4.
| Models | |||
|---|---|---|---|
| Variables | M1 | M2 | M3 |
| Concentration | |||
| Suppliers (log) | -0.081** | -0.04 | |
| (0.027) | (0.026) | ||
| Customers (log) | 0.135*** | 0.114*** | |
| (0.022) | (0.022) | ||
| Influence | |||
| Suppliers (log) | -0.251*** | ||
| (0.033) | |||
| Customers (log) | -0.077** | ||
| (0.029) | |||
| DP (log) | 0.315*** | 0.363*** | 0.396*** |
| (0.022) | (0.024) | (0.023) | |
| Market Cap (log) | -0.007 | -0.026 | -0.020 |
| (0.019) | (0.025) | (0.023) | |
| GICS sector indicators | incl. | incl. | incl. |
| Country of Risk indicators | incl. | incl. | incl. |
| Constant | 7.284*** | 7.538*** | 5.599*** |
| (0.159) | (0.201) | (0.303) | |
| Observations | 676 | 676 | 676 |
| R2 | 0.6806 | 0.6997 | 0.7319 |
| Adjusted R2 | 0.6642 | 0.6832 | 0.7163 |
| ΔR2 (bps; from M1) | 191 | 513 | |
Table 2: Regression results; Full table available in the Appendix. *p<0.05; **p<0.01; ***p<0.001$.
We find a relationship between CDS spreads and the various inter-organizational variables. Specifically, Model 2 shows that having many large suppliers lowers the CDS spread while having large customers increase the spread. The latter feature is maintained in Model 3 when including influence variables. Both influence variables are negatively related to spread. This indicates that higher default probabilities of partners are associated with lower spreads of the focal company. This effect suggests that financially healthy focal companies prioritize profit maximization over overall stability in their inter-organizational network by, for example, squeezing their suppliers’ profit margins, which in turn is detrimental to their financial health. For example, Walmart has the potential exerting pressure on suppliers if it represents a large proportion of their revenue. As such, it does seem that local optimization is favored over global optimization.
The inter-organizational variables increase the explanatory power of the framework. By including concentration and influence variables, the R2 increases from 0.68 to 0.73. This 513bps increase suggests that inter-organizational variables provide novel and additional insight into CDS spreads.
For a more comprehensive set of variable-combinations, see Table 5 in the Appendix. It is worth noting that some of these combinations bring about greater model improvement, but we have chosen the simpler operationalizations of concentration and influence in Table 2. To ensure an identical sample, we set the suppliers’ (customers’) average default probability to the average of observed values when missing as 61 companies have either no suppliers or no customers with a defined default probability. An alternative to Model 3 with these observations dropped increases the R2 to 0.8220. To be conservative, we choose the identical larger sample used in Models 1 and 2 with lower model improvement for comparability. As a robustness check, the analysis was conducted on the complete set of observation (i.e., including financial institutions) and the model improvement was maintained albeit with smaller R2 values (m1: 0.6231; m2: 0.6300; m3: 0.6585; Δm2: 69bps; Δm3: 354bps).
4. Conclusion and discussion
This project has shown that the inclusion of inter-organizational network variables increases the explanatory power of models predicting the CDS spreads, and in general the financial health of companies. We applied a simple OLS regression framework and found an increase in R2 of 191bps and 513bps when including concentration and influence variables, cumulatively. These results have direct applicability to credit risk framework, and suggests that they can be improved by including inter-organizational network information.
The analysis performed in this paper has a number of limitations. Chief among those is the simplicity of the analysis performed. It would surely be improved in more advanced models. For example, we applied a static framework, but spreads vary over time and the volatility could be modeled. Additionally, the supply-chain data used is solely available for public companies. While attempting to mitigate inclusion probability, this limits the applicability of the analysis. Moreover, we did not collect sufficient data to analyze network constraint due to the non-incremental effect of the Herfindahl index over the number of relationships. Finally, although CDS spreads are market variables, they are impacted by algorithmic trading. In turn, this might imply that they are converging around an aggregation of the various trading algorithms used.
A number of avenues of future work exist. We are particularly interested in appending the inter-organizational network variables to other existing credit risk frameworks, such as probability of default models. This would enable an understanding of whether network variables do increase the explanatory power in advanced frameworks predicting the default likelihood.
References
Aral, S., Muchnika, L., Sundararajana, A., 2009. Distinguishing influence-based contagion from homophily-driven diffusion in dynamic networks. Proceedings of the National Academy of Sciences 106(51), 21544-21549.
Bae, J., Gargiulo, M., 2004. Partner substitutability, alliance network structure, and firm profitability in the telecommunications industry. Academy of Management Journal 47(6), 860-875.
Bloomberg, 2013. Bloomberg credit risk DRSK: Framework, Methodology & Usage. Bloomberg L.P.
Brass, D.J., Galaskiewicz, J., Greve, H.R., Tsai, W., 2004. Taking Stock of Networks and Organizations: A Multilevel Perspective. Academy of Management Journal 47(6), 795-817.
Burt, R.S., 1992. Structural holes: The social structure of competition. Harvard University Press
Cross, R., Parker, A., Sasson, L., 2003. Networks in the Knowledge Economy. Oxford University Press.
Fuller, W.A., 2009. Sampling Statistics. Wiley.
Longstaff, F., Neis, E., Mithal, S., 2005. Corporate yield spreads: Default risk or liquidity? New evidence from the credit-default swap market. Journal of Finance 60(5), 2213-2253.
McPherson, J.M., Smith-Loving, L., Cook, J., 2001. Birds of a feather: Homophily in social networks. Annual review of sociology 27, 415-444.
Opsahl, T., Agneessens, F., Skvoretz, J., 2010. Node centrality in weighted networks: Generalizing degree and shortest paths. Social Networks 32 (3), 245-251.
The content of this post and accompanying paper does not reflect the opinion of the employeer of the author(s). Responsibility for the information and views expressed in the therein lies entirely with the author(s).
Unlike previous posts, I am unable to upload the data due to licensing. As such, I have attempted to describe the data processing in great detail and provided a substantial appendix in the paper.
Entry filed under: Articles, Network thoughts. Tags: arcs, centrality, complex networks, edges, graphs, Links, network, nodes, social network analysis, strength of ties, ties, valued networks, vertices, weighted networks.
 RSS feed
RSS feed

Subscribe to the comments via RSS Feed