Thesis: 5.2 Weighted network functions
For weighted networks, the main functions are transitivity (clustering_w), the weighted rich-club effect (weighted_richclub), and centrality measures (degree_w, closeness_w, and betweenness_w). The transitivity and the weighted rich-club effect functions calculate the coefficients proposed in Chapters 2 and 3, respectively. However, since all the weighted centrality measures have not been discussed in detail in this thesis, they will be briefly introduced here. They are generalisations of the three measures that Freeman (1978) originally proposed, namely degree, closeness and betweenness. The original measures were formalised as follows (equations 13a, 13b, and 13c):
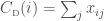
![C_{\text{\tiny{C}}}(i) = \left[ \sum_{j=1}^{N} d(i,j) \right]^{-1}](https://s0.wp.com/latex.php?latex=C_%7B%5Ctext%7B%5Ctiny%7BC%7D%7D%7D%28i%29+%3D+%5Cleft%5B+%5Csum_%7Bj%3D1%7D%5E%7BN%7D+d%28i%2Cj%29+%5Cright%5D%5E%7B-1%7D+&bg=ffffff&fg=414141&s=0&c=20201002)
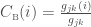
where i is the focal node, j and k are all the other nodes in the network, x is the adjacency matrix with 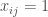


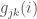
These measures have been extended to weighted network as follows. First, “degree” in weighted networks is often taken as the sum of weights (see Chapter 3 and Barrat et al., 2004; Caldarelli, 2007; Newman, 2004a; Opsahl et al., 2008), and labelled node strength. This property has been formalised as follows (equation 14):

where 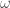
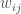
degree_w calculates both this and Freeman’s (1978) version of degree centrality.
Second, both the closeness and betweenness measures rely on the calculation of shortest distances in the network (Wasserman and Faust, 1994). Closeness centrality is the inverse of the sum of the shortest distances from a focal node to all the other reachable nodes in the network, whereas betweenness centrality measures the number of shortest paths among all other nodes that the focal node is part of. Therefore, a first step towards extending these measures to weighted networks is to generalise how shortest distances are defined.
There has been great interest in distances among nodes in networks, and in particular the shortest distance between two nodes (Dijkstra, 1959; Katz, 1953; Peay, 1980; Yang and Knoke, 2001). A key assumption used when analysing the shortest distances is that intermediary nodes increase the cost of the interaction between two nodes. First, the more intermediary nodes, the more time the interaction between two nodes takes. Second, the intermediaries can distort information or delay the interaction between other nodes (Simmel, 1950; Burt, 1992). Since all ties have the same weight in binary networks, the shortest path for interaction between two nodes is through the smallest number of intermediary nodes. However, a complication arises when the ties in a network do not have the same weight attached to them. For instance, diseases are more likely to be transferred from one person to another if they have frequent interaction (Valente, 1995). This has implications for the diffusion in networks if a backbone of strong ties exists. In fact, it has been shown that nodes heavily involved in the network activity tend to be strongly connected with one another (see Chapter 3 and Opsahl et al., 2008). Therefore, diffusion is likely to occur quicker among these nodes than would be the case if all ties carried the same weight.
There have been several attempts to calculate shortest distances in weighted networks (Katz, 1953; Dijkstra, 1959; Peay, 1980; Fisek et al., 1992; Yang and Knoke, 2001). Dijkstra (1959) proposed an algorithm that finds the path of least resistance. This algorithm was defined for networks where the weights represented costs of transmitting, e.g. number of miles for distance calculations in GPS devices or time to transfer Internet traffic between routers (Ash, 1997). The distance between two nodes is the sum of the costs attached to each tie. Newman (2001c) applied Dijkstra’s algorithm to a scientific collaboration network by inverting the positive weights in the network (see Figure 19a and b). Thus, high values represented weak or costly ties, whereas low values represented strong or cheap ties. For example, if two nodes are connected through a tie that has a weight twice as large as the weight of the tie connecting another pair of nodes, the distance between the former nodes is considered to be half the distance between the latter (e.g., the AC-dyad and the BC-dyad). The distance_w-function calculates the weighted distance matrix based on this method (see Figure 19c) (This function relies on the RBGL package that is freely available through R‘s repositories, CRAN.).

By using a distance matrix computed with Dijkstra’s algorithm, Newman (2001c) extended the closeness measure by taking the inverse row sums of this matrix. He applied both Freeman’s closeness measure and the generalised one to a coauthorship network. He found that different authors had the highest closeness score in the binary and weighted assessment. This highlights the importance of considering the weights, and suggests that the binary measure is not a good proxy of the weighted one. This algorithm is implemented in tnet as the closeness_w function.
In the case of betweenness, if the researcher assumes that the flow in the network occurs over the paths that Dijkstra’s algorithm identifies, then it is possible to use this algorithm to find the nodes that funnels the flow in the network. I have extended Freeman’s (1978) betweenness measure by counting the number of paths found by Dijkstra’s algorithm on a weighted network instead of the number found on a binary network. This extension is implemented as the betweenness_w function (This function relies upon the sp.between-function in the RBGL package. This function currently does not find more than one shortest path connecting two nodes even if an equally short path exists. This limitation affects the betweenness_w-function.).
In addition, there are two functions that create random weighted networks. First, rg_w takes a set of properties, and according to these properties it produces a random network. These properties included the number of nodes and ties, the range of weights, and whether the resulting network should be directed. Second, rg_reshuffling_w takes an observed network and randomises certain properties, such as the creator node, target node, or the location of the weights. In fact, the latter function is used by weighted_richclub when creating corresponding random networks (see Chapter 3).

Trackback this post | Subscribe to the comments via RSS Feed