Thesis: 2.2 Generalised clustering coefficient
We can generalise the clustering coefficient, C, to take tie weights into consideration by rewriting Equation 2 and defining a triplet value, 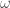

Once an appropriate method for defining

The generalised clustering coefficient produces the same result as the binary clustering coefficient if applied to a binary network. This is because all triplets have the same value, 


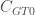

Table 2: Simulations of the generalised clustering coefficient on ensembles of classical random networks with 50, 100, 200, 400, 800, and 1,600 nodes and an average degree of 10 where ties are assigned a random weight between 1 and 10. Each ensemble contains 1,000 scenarios. The four methods for defining triplet value were not significantly different (p>0.7).
In this chapter, we assume that weights are positive values and that a higher value is better than a lower one. In situations where the second part of this assumption is not appropriate, e.g. when weights of ties refer to costs and lower values are better than higher ones, weights should be inverted (Newman, 2001c). Then, in the example of costs, a low cost will have a higher value than a high cost. Furthermore, we will use the absolute values of weights without normalising them (e.g., by dividing them by their maximum or average) as this would have no effect on the results of our analysis.
To illustrate and exemplify the applicability of the generalised clustering coefficient, Figure 2 shows two sample networks with six nodes and six weighted ties. In network a, the ties between the nodes that form the triangle have a higher weight than the average tie weight in the network, whereas the reverse is exemplified in network b.

Figure 2: Two weighted sample networks.
Both sample networks have the same binary clustering coefficient if the networks are transformed by setting ties with a weight greater than 0 (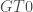

However, we believe it is not accurate to claim that both these networks have the same tendency of “friends to be friends themselves” (Freeman, 1992). Friendship can be assessed using the same criteria that Granovetter (1973) used for defining tie weights (duration, emotional intensity, intimacy, and exchange of services). If, for example, the tie weights in the sample networks in Figure 2 correspond to duration, we can say that the nodes in network a are spending more time on other nodes that are themselves tied together than in network b. In turn, it could be argued that node B‘s friendships are transitive in network a, whereas the node’s acquaintances are transitive in network b.
The generalised clustering coefficient shows a difference between the two sample networks. For network a and b in Figure 2, the coefficients obtained by using the “geometric mean” method for defining the triplet values (

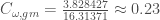
The difference between the two coefficients results from the fact that the generalised clustering coefficient captures more information than the binary one. In fact, the difference between Equation 5a and 5b is a reflection of the differences in tie weights of the two sample networks. Burt (1992, 2005) defined a person as a less efficient information broker if he or she spends time with people that are themselves connected or part of the same group. Conversely, if the person spends time with disconnected people or people part of different groups, he or she could act as a gateway and control the information flowing between the people or groups. If the sample networks were knowledge networks, it can be argued that the people in network a are less efficient in being brokers and are in less advantageous positions to control information than the ones in network b.
The weight of the closing tie of a triplet is not considered in the proposed generalisation of the clustering coefficient. This is because we believe that the aim of the clustering coefficient is to assess the likelihood of the closing tie to be created, and not the strength of this tie. Formally, we see the closing tie as a product of the triplet. In other words, as networks evolve over time by the creation and removal of ties, clustering occurs when a triplet exists and a third tie is created, so that the triplet is closed. However, in a cross-sectional network, we only observe a triangle and cannot determine which of the three triplets, that make up the triangle, occurred first. In effect, this means that the weight of the closed tie of a triplet is considered since it is part of the other two triplets in the triangle. Chapter 4 extends the proposed generalised coefficient to weighted longitudinal networks.
_____________________
¹ This finding is based on the empirical networks presented in Section 2.3. For each network, we reshuffled the weights globally among the ties in the network, and calculated
2 Comments Add your own
Leave a comment
Trackback this post | Subscribe to the comments via RSS Feed

1. Lauren Brent | April 22, 2012 at 2:43 pm
Lauren Brent | April 22, 2012 at 2:43 pm
Dear Tore,
tnet is very useful and I appreciate how intuitive/easy to implement the scripts you’ve written are. I am, however, having problems with the generalised (network-level) clustering coefficient. My network has 21 nodes with a max dyadic tie weight of 0.076 interactions/hour. The binary clustering coefficient is 0.6 (which is agreement with what other software packages tell me), but the weighted values tnet produces (the geometric mean and max value) are greater than 1. This is not possible, correct? Have you ever encountered this and what (e.g. errors in the data) might produce such a result? I’ve poured over my data and can’t find the problem. Thanks so much!
2. Tore Opsahl | April 23, 2012 at 12:55 pm
Tore Opsahl | April 23, 2012 at 12:55 pm
Hi Lauren,
Thanks you for your feedback. The clustering coefficients should not get a value over 1. Could you send me your network and code in an email and then I will look into it in detail.
Best,
Tore