Thesis: 2.1 Clustering coefficient
An article based on this chapter has been published
(Opsahl and Panzarasa, 2009). This article was written after this chapter and contains a number of changes.
The global clustering coefficient is based on triplets of nodes. A triplet is three nodes that are connected by either two (open triplet) or three (closed triplet) undirected ties. The global clustering coefficient is the number of closed triplets over the total number of triplets (both open and closed). The number of closed triplets has also been referred to as 3  triangles in the literature. This is due to the fact that three closed triplets form a triangle, one triplet centred on each of the three nodes in the triangle. The first attempt to measure the coefficient was made by Luce and Perry (1949). For an undirected network, they showed that the total number of triplets could be found by summing the non-diagonal cells of a squared binary matrix. The number of closed triplets could be found by summing the diagonal of a cubed matrix. For clarity, we will refer to the global clustering coefficient as the binary clustering coefficient, C (equation 2):
triangles in the literature. This is due to the fact that three closed triplets form a triangle, one triplet centred on each of the three nodes in the triangle. The first attempt to measure the coefficient was made by Luce and Perry (1949). For an undirected network, they showed that the total number of triplets could be found by summing the non-diagonal cells of a squared binary matrix. The number of closed triplets could be found by summing the diagonal of a cubed matrix. For clarity, we will refer to the global clustering coefficient as the binary clustering coefficient, C (equation 2):

where  is number of triplets and
is number of triplets and  is the subset of these triplets that are closed by the addition of a third tie. The coefficient takes values between 0 and 1. In a completely connected network
is the subset of these triplets that are closed by the addition of a third tie. The coefficient takes values between 0 and 1. In a completely connected network  as all triplets are closed, whereas in classical random networks
as all triplets are closed, whereas in classical random networks 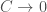 as the network grows. More specifically, in classical random networks, the probabilities that dyads (i.e., pairs of nodes) are tied together are by definition independent (Erdos and Renyi, 1959; Solomonoff and Rapoport, 1951). Therefore, C is equal the probability of a tie in these networks (Newman, 2003).
as the network grows. More specifically, in classical random networks, the probabilities that dyads (i.e., pairs of nodes) are tied together are by definition independent (Erdos and Renyi, 1959; Solomonoff and Rapoport, 1951). Therefore, C is equal the probability of a tie in these networks (Newman, 2003).
A major limitation of the binary clustering coefficient is that it cannot be applied to a weighted network. As a result, the same outcome might be attributed to networks with different likelihoods of friends being friends with each other. This could bias the analysis of the network structure. In order to overcome this shortcoming, in the following section we will introduce a generalisation of the clustering coefficient that captures the richness of tie weights, while at the same time producing the same outcome as the binary clustering coefficient when all ties have the same weights (i.e., a binary network).

Trackback this post | Subscribe to the comments via RSS Feed