Thesis: 4.2 Cross-sectional binary networks
Despite the identification of these mechanisms, the literature does not provide many statistical models for appropriately analysing the combined effects of these mechanisms and the evolution of networks in general (Frank and Strauss, 1986; Robins and Pattison, 2001; Snijders, 2001; Snijders et al., 2008; Wasserman and Pattison, 1996). The lack of appropriate models stems from the fact that most networks are collected in a cross-sectional way (e.g., a snapshot of the network is collected at a single point in time). Thus, the dependency structure among the ties is unknown. This increases the complexity of modelling efforts. For example, if a triangle is observed in a static network, it is not possible to determine which of the three ties closed the triplet formed by the other two ties.
A basic assumption often applied in statistical models is that observations are independent of each other. One model with this assumption is the logistic regression model. This is a statistical model that allows for a discrete choice or binary dependent variable (Hosmer and Lemeshow, 2000; Long and Freese, 2003). Thus, it could be applied to a binary network to predict the presence or absence of ties in a binary network, where the observations would be all possible ties. The dependent variable for the tie 
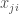


Figure 11: Example of dependence among ties. All the ties share the common node i.
Holland and Leinhardt (1981) were among the first to propose a model where ties were seen as a stochastic function of node or network properties. Their 
To overcome the problems of the 
The ERG model has extensively been used to predict the combined effects of mechanisms that guide tie formation in networks (see the special issue in the journal Social Networks edited by Robins and Morris, 2007, for a review of developments and applications). This model takes the observed cross-sectional network structure as the dependent variable, and tries to model the factors that led to its creation. We will focus on the ERG model for the remaining of this chapter as the
These terms are network sub-configurations that operationalise different mechanisms thought to guide tie formation. The most common terms for directed networks are density, star-configurations, reciprocity, triadic closure, homophily, and focus constraint effects (Robins and Morris, 2007). First, the density term is a “constant” in the model that controls for the number of ties in the network. This term should be included to limit degeneracy. A degenerate model is a model that predicts a fully connected (i.e., all possible ties are formed) or empty (i.e., no ties are formed) network (Handcock, 2003; Snijders, 2002). When this occurs, the coefficients of the model cannot be relied upon.
Second, a set of different star-configurations are often included to account for expansiveness and popularity mechanisms in a network (skewed degree distributions). For example, a 2-in-star configuration is the number of occurrences of two ties terminate at the same node. This term would account for popularity in a network. The star-configurations have caused a number of interpretation and modelling difficulties. For example, for undirected networks, Robins et al. (2005) found models with positive 2-star parameters and negative 3-star parameters. From this result, their “substantive interpretation” was that nodes tend to expansive (positive two-star), but experience a cost in forming too many ties (negative three-star) (p. 913). In addition, when these terms are included, the models often do not converge (i.e., stable parameters that described the network could not be found). To overcome these modelling issues, alternating k-stars were introduced by Robins et al. (2007). However, these did not improve the ease of interpretation as they are a function of positive even-numbered star configurations and negative odd-number ones.
Third, the number of dyads consisting of two directed ties is often included in the model. If it is not and reciprocity is an effect in the network, then there would be more dyads with at least one tie. Thus, to control for the total number of connected dyads in the network and to account for the effect of reciprocity, this term is often included.
Fourth, the likelihood of observing triangles in networks can be accounted for by using a number of terms. The most common term is the number of transitive triplets in a network. This term would control for the tendency of two nodes to be tied if they tied to the same other node (see Chapter 2 and Holland and Leinhardt, 1971).
Finally, various terms have been included to describe homophily and focus constraints based on covariates or attributes of the nodes contained in the datasets. For example, if information about nodes’ gender are included in a social network dataset, it is possible to test whether two people of the same gender are more likely to form a tie than two people of different gender.
This model is formalised as follow:
where Y is an ensemble of random networks, y is the observed network, 
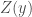
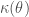

This model has been variously implemented in the three publicly available software packages that estimate ERG models: Pnet (Wang et al., 2005), Siena (Snijders et al., 2007), and Statnet (Handcock et al., 2003). In Siena, in addition to the above list of terms and a range of less common terms, interaction terms can be introduced in a similar fashion as in a standard multivariate regression. This allows for a better understanding of how various terms combine to affect the likelihood of a tie.
Furthermore, a related model to ERG model has been proposed by Snijders (2001) and collaborators (Snijders et al., 2008). They proposed a panel model that takes multiple observations of a network over time to study network evolution. This model is referred to as the SIENA model (implemented in the Siena software; Snijders et al., 2007). (This model might have been more appropriate for Powell et al. (2005) since they used yearly snapshots.) The panel model has a number of advantages. It allows for a deeper understanding of different processes, such as selection and influence (Steglich et al., 2007). Selection terms are seen as factors that “attracts” ties, whereas influence terms are factors responsible for the changing of behaviour as a result of a social tie. The classical example is that of 129 pupils at a high school in Scotland where the social structure was observed at each year (1995-1997) from when they were roughly 13 to 15 (Pearson and Michell, 2000; Pearson and West, 2003). Using this model, Steglich et al. (2007) were able to differentiate whether smoking behaviour and alcohol consumption made pupils friends with each other (selection) or whether social ties affected the smoking behaviour and consumption of alcohol (influence).
A main shortcoming of the ERG and SIENA models is that the denominator or normalising factor cannot feasibly be calculated (Snijders, 2002; Wasserman and Pattison, 1996). This shortcoming stems from the fact that only a single snapshot of the network (or a limited number of snapshots for the SIENA model) is known. A consequence of this fact is that the exact sequence in which ties were formed and severed is unknown, which in turn, requires the entire network to be modelled at the same time (the dependent variable in the model is the entire observed network). The maximum likelihood procedure cannot be exact due to the extremely large number of possible realisations that random networks can take if there are more than a few nodes. Therefore, approximation procedures have been applied to detect coefficients that are close to the exact ones. Traditionally, the models relied upon a pseudo-likelihood estimation procedure (Wasserman and Pattison, 1996). However, this method has been found to estimate coefficients that are not close to the exact ones, and to produce unreliable standard errors (Snijders, 2002). Currently, a Markov chain Monte Carlo (MCMC) procedure is the recommended method for attaining coefficients that are close to the exact ones as well as determining their significance.

Trackback this post | Subscribe to the comments via RSS Feed