Thesis: 3.1 The topological rich-club effect
This work draws on, and extends, the topological measure of the rich-club phenomenon (Colizza et al., 2006; Zhou and Mondragon, 2004), that quantifies the extent to which the nodes with a high degree (i.e., the number of ties originating from a node, k) are connected with each other to a greater extent than randomly expected. In this measure, the prominent nodes are defined as the hubs that preside over many ties with other nodes. This choice was based on the discovery of skewed degree distributions (i.e., the probability that a given tie has degree k, 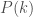
Formally, the topological rich-club coefficient is the proportion of ties connecting prominent nodes, with respect to the maximum possible number of ties among them. For the set of prominent nodes with degree larger than k, 

where 
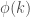
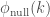
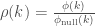
This ratio enables us to examine the extent to which the observed rich-club phenomenon diverges from what would be expected by chance.
A positive topological rich-club phenomenon has been found in networks of scientific collaborations among researchers (Colizza et al., 2006), in transportation networks (Colizza et al., 2006; Opsahl et al., 2008), in the Italian interbank network (De Masi et al., 2006), and in content-based networks (Balcan and Erzan, 2007). On the contrary, a negative tendency was found for the Internet, where highly connected routers are not typically connected with one another (Colizza et al., 2006). Biological networks, such as protein-protein interaction networks, do not show a consistent trend. Studies suggests that the trends are related to specific features of the organisms under study (Colizza et al., 2006; Guimera et al., 2007; Wuchty, 2007).

Trackback this post | Subscribe to the comments via RSS Feed