Thesis: 4.7 Conclusion and discussion
In this Chapter, we applied a well-tested regression framework, often used in epidemiology (conditional logistic regression; Cox and Hinkley, 1974) and economics (choice modelling; McFadden, 1973), to the study of the principles underpinning network evolution. In economics, this framework is used to model the decision-making process of people in various settings, whereas in epidemiology it is used to model the factors that affect a specific medical condition, such as a particular cancer (e.g., Pastides et al., 1983). We proposed to apply this framework to the decisional processes of nodes when creating ties.
Nodes do not form ties with others randomly (Erdos and Renyi, 1960; Holland and Leinhardt, 1981; Solomono and Rapoport, 1951; Snijders, 2001; Wasserman and Pattison, 1996). Conversely, they are likely to direct their ties towards other nodes with whom they have common contacts (Heider, 1946), popular nodes (Barabasi et al., 2002), similar nodes (McPherson et al., 2001), and nodes with whom they share geographical location or institutional context (Feld, 1981). However, due to the fact that most networks are collected at a single point in time, it is difficult to analyse the choices that nodes make when forming a tie. In fact, a range of methods have been developed to simulate the sequence in which ties are formed, and then analyse the decision process of nodes (Snijders, 2001; Snijders et al., 2008).
We did not pursue this line of investigation. Conversely, we studied a new type of network data that have become available in recent years: longitudinal network data (e.g. Hall et al., 2001; Holme et al., 2004; Kossinets and Watts, 2006; Onnela et al., 2007; Panzarasa et al., 2009). A special feature of this type of data is that the exact sequence of ties is known and, therefore, we can measure the properties, such as in-degree, of all nodes available in the network to whom a node could have directed a tie at the time the tie was formed. Based on the properties of potential targets of a tie, we were able to model the decision processes of nodes.
This method was applied to a social network constructed from a virtual community. The nodes of the network were college students who could create ties with each other by send online messages. This network is a prototypical evolving social network where the nodes are people who are in control of their outgoing ties. Therefore, it allowed us to explore the general regularities governing the initiation and progression of interpersonal dynamics.
The findings clarify and extend past research by focusing on critical issues that tend to be overlooked in studies of the evolution of networks, such as directionality and reinforcement. We first dichotomised the network and tested independently a number of mechanisms leading to the generation of new ties. We found support for triadic closure, popularity, reciprocity, homophily, and focus constraint when tested independently. The only exception was gender homophily which proved to have a negative effect on the evolution of the network.
A key benefit of using a regression framework is the possibility of testing multiple effects at the same time. This allowed us to study how effects jointly drive network evolution. Results were consistent with the independent tests, except for the triadic closure and similar age terms that became insignificant. We speculated that the significance results obtained in the independent tests were due to multicollinearity. Moreover, the effect of in-degree was mitigated in the multivariate analysis.
Furthermore, we extended the method to cover weighted networks by relaxing some of the assumptions made by the model and adding terms specifically designed for weighted networks. We found strong support in favour of reinforcement, thereby suggesting that students are much more likely to communicate with someone they have already communicated with. Moreover, the results were roughly consistent with the analysis of the binary network. In particular, we found a further mitigation of in-degree. In addition, we generalised triadic closure using two of the methods for calculating triplet values proposed in Chapter 2. The generalised term based on the minimum method for calculating triplet values was significant (
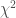
The lack of a strong positive and significant effect of having common friends on tie generation in the online social network is surprising as this generally a strong effect in networks (Snijders, 2001; Wasserman and Pattison, 1996). In most offline social settings, communication occurs in groups larger than two. In these settings, the contacts of an individual can observe each other. Conversely, in the virtual community, individuals could only communicate one-to-one. Thus, an individual's contacts could not observe each other. Furthermore, in May 2008, the virtual community Facebook launched a service called People You May Know (http://blog.facebook.com/blog.php?post=15610312130), which proposed new possible contacts to an user. This feature was heavily based on common contacts. However, in September when a new interface was launched, this service did no longer form part of the first page users see when logging in. The reduce of focus might suggest a lack of use due to inaccuracy by relying on common friends.
The empirical analysis we conducted is not without limitations. We could not verify that the messages did indeed reflect genuine interpersonal communication. A possible method for verifying whether this is the case is to study message content. However, due to privacy reasons, we could not study the content of messages. Moreover, the information supplied when the students registered for the community was not validated. Only students' email addresses were validated to guarantee that they were in fact students at the university. In addition, the dataset does not contain any information about the weakening or severing of ties. Thus, a tie created at the very start of the community was assumed to remain in the network till the end.
The proposed method is not without limitations. The main one is that required data are difficult to obtain. However, due to the increase in use of electronic medium for social interaction, such as social network sites (Leskovec et al., 2005; Wellman, 1999), and the rise of machine-readable databases with interaction data, such as online repositories of scientific papers (e.g. Newman, 2001a), we believe that this type of data is likely to become more common in the future. In addition, as we are exploring the decision processes of nodes, this method relies on networks where the nodes are in charge of their ties. This is not always the case. For example, in the movie network (Watts and Strogatz, 1998) or the Broadway musical network (Uzzi and Spiro, 2005), ties among people might not entirely reflect people's decisions as it is the casting directors that design the teams of people working together on projects.
The method developed in this chapter is general and flexible. From an actor-based perspective, researchers can test additional growth mechanisms. These could include the geodesic distance among nodes (Wasserman and Pattison, 1996) or dyadic covariates (Snijders, 2001). Furthermore, the method is not limited to social networks. For example, if the sequence in which neurons create synapses and gap junctions can be recorded, this method might yield new and interesting findings. Moreover, the method is not limited to an actor-based perspective. A dyad-based perspective might be adopted to study undirected networks. This would require new terms that take into consideration the decisional process of both nodes when forming a tie. An example of an undirected network where the exact sequence of ties is possible to map is the airport network used in Chapter 3 as routes start and terminate at specific points in time. Moreover, in this network, the weakening of ties (or decrease of capacity) also occurs at specific times.

Subscribe to the comments via RSS Feed